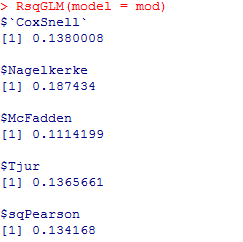
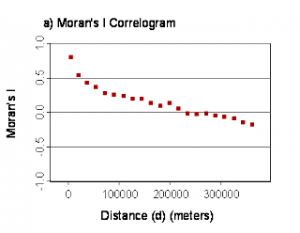
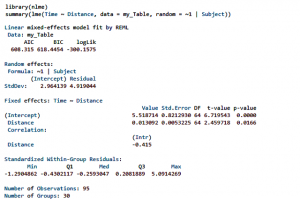
O objetivo desse curso é fornecer uma introdução teórico-prática ao uso da estatística circular para análise de eventos temporais. Para tal, nós utilizamos como base de exemplo dados de plantas para demonstração do uso de abordagens básicas da estatística circular para estudos fenológicos, isto é, para investigação de tendências unimodais (sazonais) ou multimodais (não sazonais) de eventos mensais de floração e frutificação ao longo de meses do ano. Essa exemplificação permite o entendimento interdisciplinar sobre como explorar os próprios dados contendo frequências de observações (diárias, semanais, mensais, anuais) de um determinado evento em busca de padrões sazonais. Assim, o participante aprende desde princípios teóricos até a elaboração de dados e conversão de datas de observações de eventos em ângulos geométricos para análises. Ao participante é fornecido bancos de dados teste de fenologia vegetal e protocolo para acompanhar as análises no software Oriana, o mais bem desenvolvido especificamente para estatística circular. Juntamente com a parte prática é explicada de forma introdutória a base teórica dos principais testes estatísticos aplicados em estatística circular para tal propósito e indicada literatura para manutenção de conhecimento e aprofundamento.
Carga horária: 6 horas
Ministrante: Dr. Écio Souza Diniz
Investimento: R$ 80,00
Inscrição: https://forms.gle/MvW3EANuZTidR9pi6
Pré-requisitos desejáveis: entendimento básico de estatística descritiva (ex: distribuição normal, média, moda, mediana, desvio padrão, intervalo de confiança) e uso de computador com Windows para instalação correta do software Oriana. O não preenchimento desses pré-requisitos não invalida participação no curso, mas isenta responsabilidade da empresa quanto ao participante conseguir acompanhar de forma bem sucedida os conteúdos abordados.
Conteúdo do curso:
- Introdução teórica à estatística circular
- Principais funcionalidades para investigações de sazonalidade
- Preparação dos dados
- Conversão de datas de observações em ângulos (0 a 360º)
- Testes estatísticos sobre as frequências de observações em ângulos
- Geração de histograma circular – tendências modais
- Ajustes modais para os testes estatísticos
- Interpretação dos resultados
- Sugestões de apresentação dos resultados em publicações
- Indicações de leitura de manutenção e aprofundamento