

1. R² e os pseudo-R²: qual a diferença?
Muitas pessoas, especialmente quando iniciantes, nos modelos lineares generalizados (GLM) procuram por um R² como um parâmetro explicativo da variância da variável dependente. Ao contrário do LM (linear model), que é baseado na abordagem dos quadrados mínimos ordinários (OLS – Ordinary least squares), não há R² semelhante para o GLM. Os modelos generalizados apresentam o que é chamado pseudo-R² (ou pseudo R-squared). Eles são chamados assim porque como os R² verdadeiros, eles também variam de 0 a 1, indicando que o modelo é bem ajustado e explicativo quanto maior for o valor. Contudo, a interpretação dos pseudo-R² não é similar, mas sim análoga, a dos modelos (ex: LM) baseados na OLS. Uma vez que as estimativas dos parâmetros de GLMs são normalmente a partir de estimativas de máxima verossimilhança obtidas por meio de um processo iterativo, a abordagem OLS para adequação do modelo na explicação de variância não se aplica. Há uma série de pseudo-R² para GLMs, especialmente para regressões logísticas (binomial com variável categórica binária (0 ou 1) como dependente), mas ainda sem um consenso consolidado dos melhores. Aqui faremos um apanhado geral e resumido dos pseudo-R² mais usados para GLMs com distribuições de erros em geral e também distribuições específicas (ex: Poisson).
2. D²: um parâmetro abrangente de pseudo-R² para diversos modelos GLM.
Esse índice é o mais abrangente para GLMs, pois devido a calcular a quantidade ajustada de desvio (deviance) nesses modelos, ele pode se ajustar bem a modelos com distintas distribuições de erros. A lógica do D² segue o seguinte cálculo, conforme fundamentado por (Guisan e Zimmermann 2000).
1−Residual Deviance / Null Deviance
A Residual Deviance e a Null Deviance são parâmetros que já são encontrados no summary dos GLM. O D² pode ser computado também utilizando o pacote modEvA.
2.1 Pseudo-R² para regressão logística (binomial): o caso mais abundante.
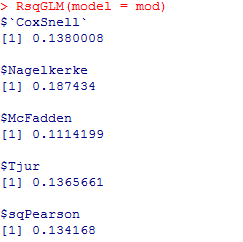
Há uma série de pseudo-R² implementados em diversos pacotes do R que foram desenvolvidos para regressão logística (variável dependente binária, 0 ou 1) via GLM com distribuição de erros binomial. Os mais conhecidos e bem desenvolvidos pseudo-R² nesse caso são: Cox & Snell, Nagelkerke, McFadden, McFadden Adjusted, Lave/Efron, and Aldrich-Nelson, Veall-Zimmerman pseudo R index, OLS R e OLS Adjusted R². Em sua publicação “A Comparison of Logistic Regression Pseudo R² Indices”, Smith (2013) compara a eficácia desses diferentes pseudo-R² para regressão logística. O pacote modEvA no R com, por exemplo, computa McFadden, Cox & Snell, Nagelkerke, além do Tjur coefficient. O pacote DescTools também fornece função para computar diversos pseudo-R² para regressão logística.
2.2 Pseudo-R² para modelos Poisson.
O mais bem ajustado pseudo-R² para modelos cuja variável dependente é contagem (Poisson), ou seja, um dado discreto, é o V de Zhang (Zhang’s V), o qual pode ser computado utilizando o pacote rsq no R. Ele se ajusta bem para modelos Poisson com sub ou sobredispersão e também para modelos negativo binomial.
3. Os pseudo-R² de diferentes modelos são comparáveis?
Quando lidamos com reais R² baseados na pura OLS, se um modelo apresenta R² = 0.80, ou seja, 80% da variação na variável resposta é explicada pelo modelo, e outro modelo para a mesma variável resposta com R² = 0.83, então podemos concluir que os dois modelos predizem otimamente tal variação, apenas com o segundo com poder preditivo um pouco maior. No entanto, essa comparação entre modelos não se torna plausível quando se trata de pseudo-R² por duas razões principais, a diferença de escala e objetivo de cada índice para pseudo-R². No R² baseado na OLS, a escala de variação vai de 0 a 1, mas, por exemplo, o pseudo-R² de Cox & Snell usado na regressão logística comumente não varia entre 0 e 1 em dois ou mais modelos sendo comparados. O objetivo de cada tipo de pseudo-R² também inviabiliza comparações de diferentes índices entre os modelos porque ao contrário da OLS que minimiza as diferenças quadradas entre as predições e os reais valores da variável resposta sendo predita, cada pseudo-R² segue seus próprios parâmetros de cálculo. Por exemplo, o Efron pseudo-R² é computado baseado na soma dos resíduos quadrados.
4-Conclusão
Os pseudo-R² somente são uteis para comparações entre múltiplos modelos quando baseados no mesmo banco de dados com o mesmo objetivo de predição para um tipo específico de resultados e comparando o mesmo tipo de pseudo-R². O uso do D² para comparações entre diferentes modelos GLM pode ser uma alternativa mais lógica, visto ser baseado de forma padronizada na razão de suas ‘residual deviance’ e ‘null deviance’.
Achou o conteúdo acima interessante? Precisa de mais informação e ajuda para trabalhar com solidez e confiabilidade na tomada de decisão de qual melhor índice utilizar e computá-lo com precisão? Venha conversar conosco!